A rule like
defines transformations for any expressions x_ and y_. So, for example, if we use the rule from left to right on the expression a∘(b∘a) the “pattern variable” x_ will be taken to be a while y_ will be taken to be b∘a, and the result of applying the rule will be ((b∘a)∘a)∘(b∘a).
But consider instead the case where our rule is:
Applying this rule (from left to right) to a∘(b∘a) we’ll now get ((b∘a)∘a)∘z_. And applying the rule to a∘b we’ll get (b∘a)∘z_. But what should we make of those z_’s? And in particular, are they “the same”, or not?
A pattern variable like z_ can stand for any expression. But do two different z_’s have to stand for the same expression? In a rule like z_∘z_ ... we’re assuming that, yes, the two z_’s always stand for the same expression. But if the z_’s appear in different rules it’s a different story. Because in that case we’re dealing with two separate and unconnected z_’s—that can stand for completely different expressions.
To begin seeing how this works, let’s start with a very simple example. Consider the (for now, one-way) rule
where a is the literal symbol a, and x_ is a pattern variable. Applying this to a∘a we might think we could just write the result as:
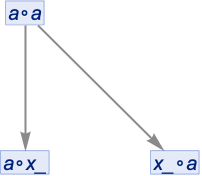
Then if we apply the rule again both branches will give the same expression x_∘x_, so there’ll be a merge in the multiway graph:
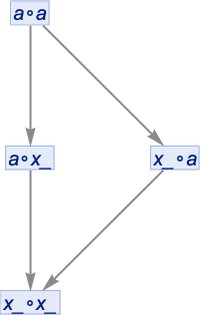
But is this really correct? Well, no. Because really those should be two different x_’s, that could stand for two different expressions. So how can we indicate this? One approach is just to give every “generated” x_ a new name:
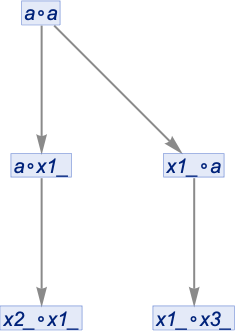
But this result isn’t really correct either. Because if we look at the second step we see the two expressions x1_∘x3_ and x2_∘x4_. But what’s really the difference between these? The names xi are arbitrary; the only constraint is that within any given expression they have to be different. But between expressions there’s no such constraint. And in fact x1_∘x3_ and x2_∘x4_ both represent exactly the same class of expressions: any expression of the form u_∘v_.
So in fact it’s not correct that there are two separate branches of the multiway system producing two separate expressions. Because those two branches produce equivalent expressions, which means they can be merged. And turning both equivalent expressions into the same canonical form we get:
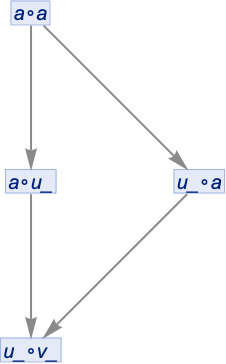
It’s important to notice that this isn’t the same result as what we got when we assumed that every x_ was the same. Because then our final result was the expression x_∘x_ which can match a∘a but not a∘b—whereas now the final result is u_∘v_ which can match both a∘a and a∘b.
This may seem like a subtle issue. But it’s critically important in practice. Not least because generated variables are in effect what make up all “truly new stuff” that can be produced. With a rule like x_∘y_(y_∘x_)∘y_ one’s essentially just taking whatever one started with, and successively rearranging the pieces of it. But with a rule like x_∘y_(y_∘x_)∘z_ there’s something “truly new” generated every time z_ appears.
By the way, the basic issue of “generated variables” isn’t something specific to the particular symbolic expression setup we’ve been using here. For example, there’s a direct analog of it in the hypergraph rewriting systems that appear in our Physics Project. But in that case there’s a particularly clear interpretation: the analog of “generated variables” are new “atoms of space” produced by the application of rules. And far from being some kind of footnote, these “generated atoms of space” are what make up everything we have in our universe today.
The issue of generated variables—and especially their naming—is the bane of all sorts of formalism for mathematical logic and programming languages. As we’ll see later, it’s perfectly possible to “go to a lower level” and set things up with no names at all, for example using combinators. But without names, things tend to seem quite alien to us humans—and certainly if we want to understand the correspondence with standard presentations of mathematics it’s pretty necessary to have names. So at least for now we’ll keep names, and handle the issue of generated variables by uniquifying their names, and canonicalizing every time we have a complete expression.
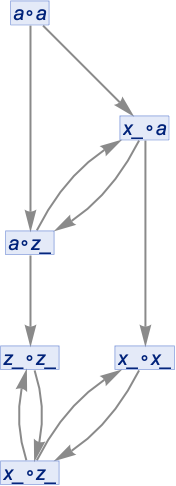
Let’s look at another example to see the importance of how we handle generated variables. Consider the rule:
If we start with a∘a and do no uniquification, we’ll get:
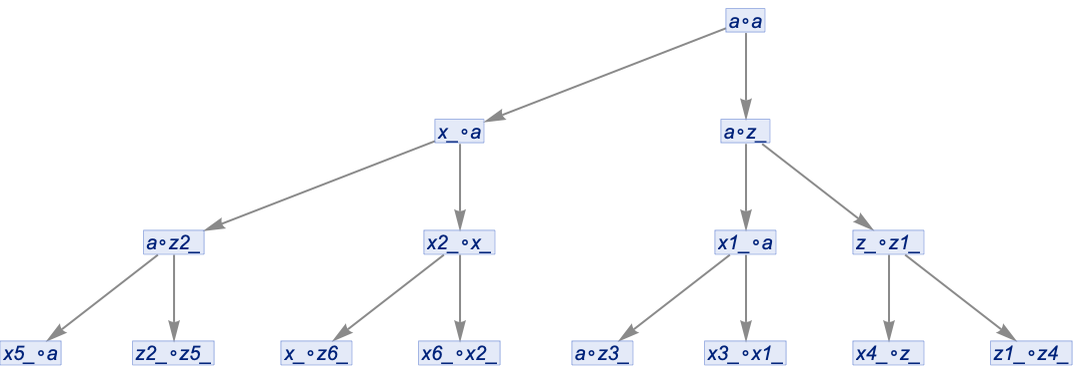
With uniquification, but not canonicalization, we’ll get a pure tree:
But with canonicalization this is reduced to:
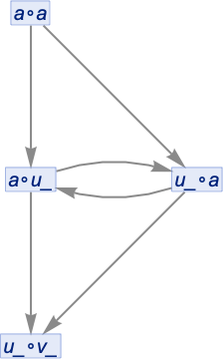
A confusing feature of this particular example is that this same result would have been obtained just by canonicalizing the original “assume-all-x_’s-are-the-same” case.
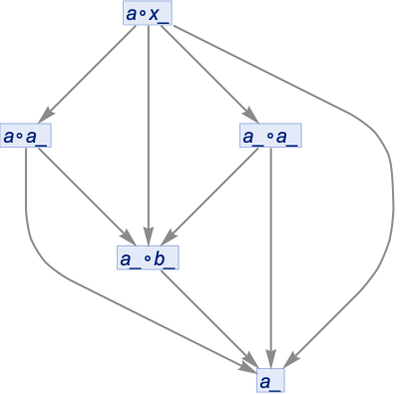
But things don’t always work this way. Consider the rather trivial rule
starting from a∘x_. If we don’t do uniquification, and don’t do canonicalization, we get:
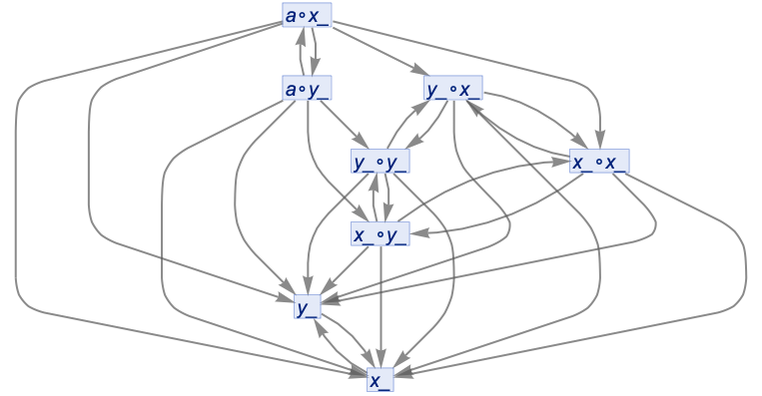
If we do uniquification (but not canonicalization), we get a pure tree:
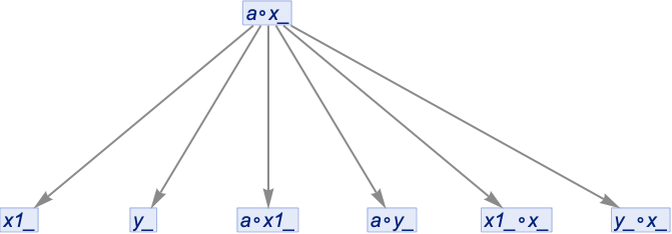
But if we now canonicalize this, we get:
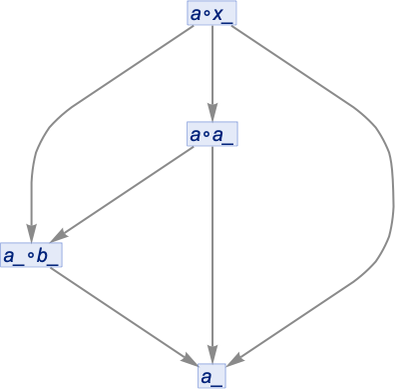
And this is now not the same as what we would get by canonicalizing, without uniquifying: