We’ve so far considered something like
just as an abstract statement about arbitrary symbolic variables x and y, and some abstract operator ∘. But can we make a “model” of what x, y, and ∘ could “explicitly be”?
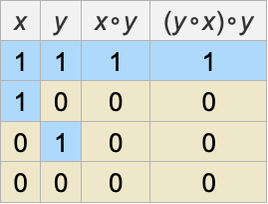
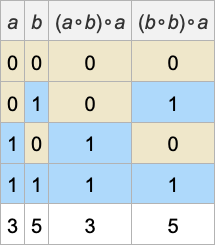
Let’s imagine for example that x and y can take 2 possible values, say 0 or 1. (We’ll use numbers for notational convenience, though in principle the values could be anything we want.) Now we have to ask what ∘ can be in order to have our original statement always hold. It turns out in this case that there are several possibilities, that can be specified by giving possible “multiplication tables” for ∘:

(For convenience we’ll often refer to such multiplication tables by numbers FromDigits[Flatten[m],k], here 0, 1, 5, 7, 10, 15.) Using let’s say the second multiplication table we can then “evaluate” both sides of the original statement for all possible choices of x and y, and verify that the statement always holds:
If we allow, say, 3 possible values for x and y, there turn out to be 221 possible forms for ∘. The first few are:

As another example, let’s consider the simplest axiom for Boolean algebra (that I discovered in 2000):
Here are the “size-2” models for this
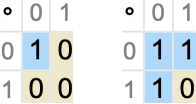
and these, as expected, are the truth tables for Nand and Nor respectively. (In this particular case, there are no size-3 models, 12 size-4 models, and in general ![]() models of size 2n—and no finite models of any other size.)
models of size 2n—and no finite models of any other size.)
Looking at this example suggests a way to talk about models for axiom systems. We can think of an axiom system as defining a collection of abstract constraints. But what can we say about objects that might satisfy those constraints? A model is in effect telling us about these objects. Or, put another way, it’s telling what “things” the axiom system “describes”. And in the case of my axiom for Boolean algebra, those “things” would be Boolean variables, operated on using Nand or Nor.
As another example, consider the axioms for group theory
Here are the models up to size 3 in this case:

Is there a mathematical interpretation of these? Well, yes. They essentially correspond to (representations of) particular finite groups. The original axioms define constraints to be satisfied by any group. These models now correspond to particular groups with specific finite numbers of elements (and in fact specific representations of these groups). And just like in the Boolean algebra case this interpretation now allows us to start saying what the models are “about”. The first three, for example, correspond to cyclic groups which can be thought of as being “about” addition of integers mod k.
For axiom systems that haven’t traditionally been studied in mathematics, there typically won’t be any such preexisting identification of what they’re “about”. But we can still think of models as being a way that a mathematical observer can characterize—or summarize—an axiom system. And in a sense we can see the collection of possible finite models for an axiom system as being a kind of “model signature” for the axiom system.
But let’s now consider what models tell us about “theorems” associated with a given axiom system. Take for example the axiom:
Here are the size-2 models for this axiom system:

Let’s now pick the last of these models. Then we can take any symbolic expression involving ∘, and say what its values would be for every possible choice of the values of the variables that appear in it:
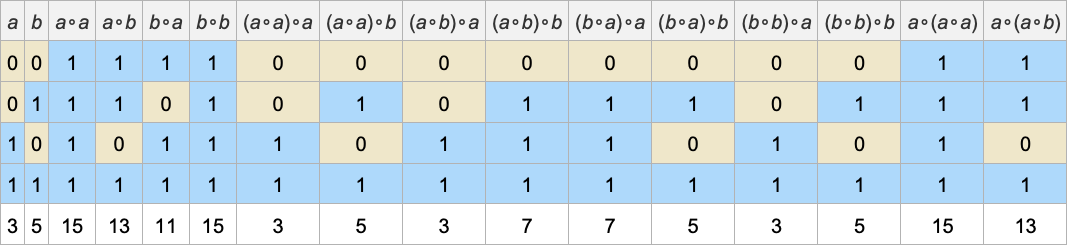
The last row here gives an “expression code” that summarizes the values of each expression in this particular model. And if two expressions have different codes in the model then this tells us that these expressions cannot be equivalent according to the underlying axiom system.
But if the codes are the same, then it’s at least possible that the expressions are equivalent in the underlying axiom system. So as an example, let’s take the equivalences associated with pairs of expressions that have code 3 (according to the model we’re using):
So now let’s compare with an actual entailment cone for our underlying axiom system (where to keep the graph of modest size we have dropped expressions involving more than 3 variables):
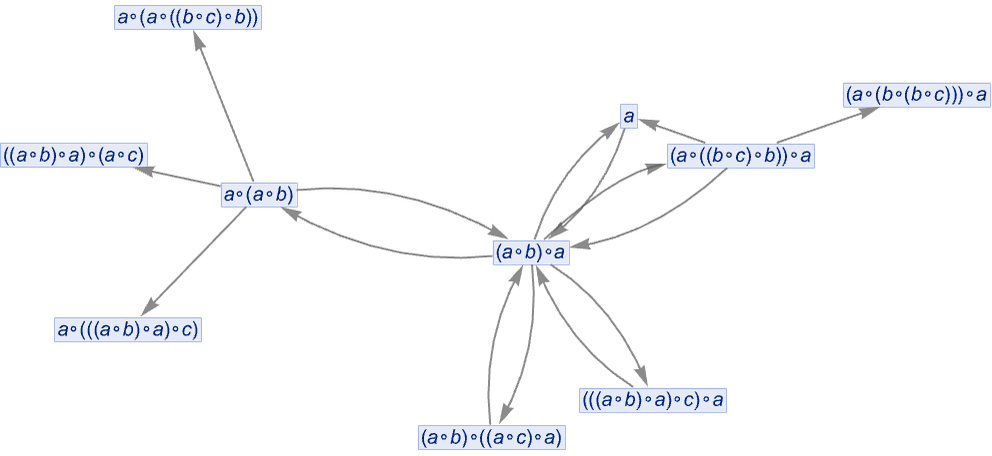
So far this doesn’t establish equivalence between any of our code-3 expressions. But if we generate a larger entailment cone (here using a different initial expression) we get
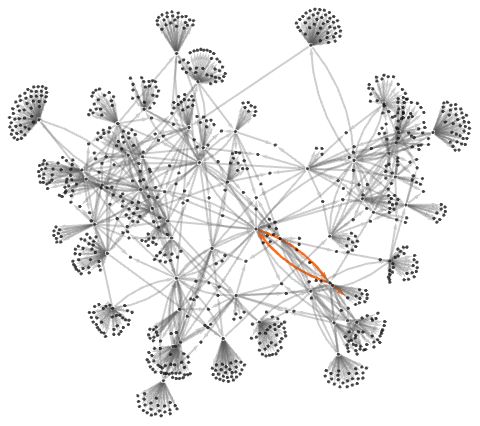
where the path shown corresponds to the statement
demonstrating that this is an equivalence that holds in general for the axiom system.
But let’s take another statement implied by the model, such as:
Yes, it’s valid in the model. But it’s not something that’s generally valid for the underlying axiom system, or could ever be derived from it. And we can see this for example by picking another model for the axiom system, say the second-to-last one in our list above
and finding out that the values for the two expressions here are different in that model:
The definitive way to establish that a particular statement follows from a particular axiom system is to find an explicit proof for it, either directly by picking it out as a path in the entailment cone or by using automated theorem proving methods. But models in a sense give one a way to “get an approximate result”.
As an example of how this works, consider a collection of possible expressions, with pairs of them joined whenever they can be proved equal in the axiom system we’re discussing:
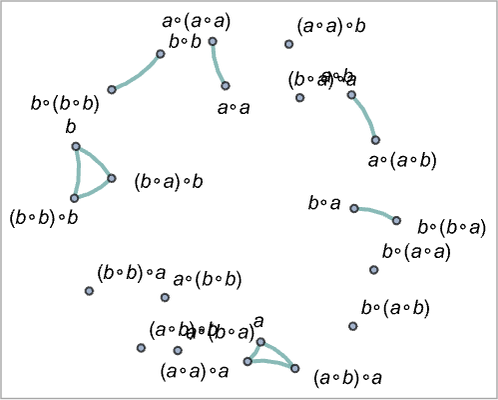
Now let’s indicate what codes two models of the axiom system assign to the expressions:
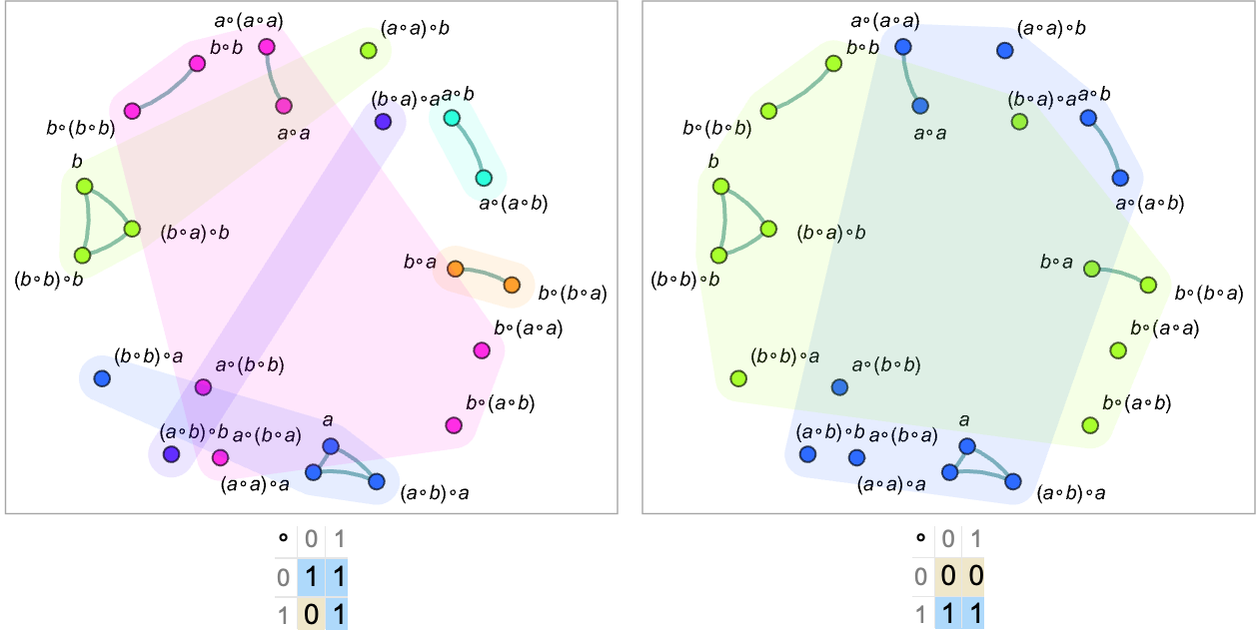
The expressions within each connected graph component are equal according to the underlying axiom system, and in both models they are always assigned the same codes. But sometimes the models “overshoot”, assigning the same codes to expressions not in the same connected component—and therefore not equal according to the underlying axiom system.
The models we’ve shown so far are ones that are valid for the underlying axiom system. If we use a model that isn’t valid we’ll find that even expressions in the same connected component of the graph (and therefore equal according to the underlying axiom system) will be assigned different codes (note the graphs have been rearranged to allow expressions with the same code to be drawn in the same “patch”):
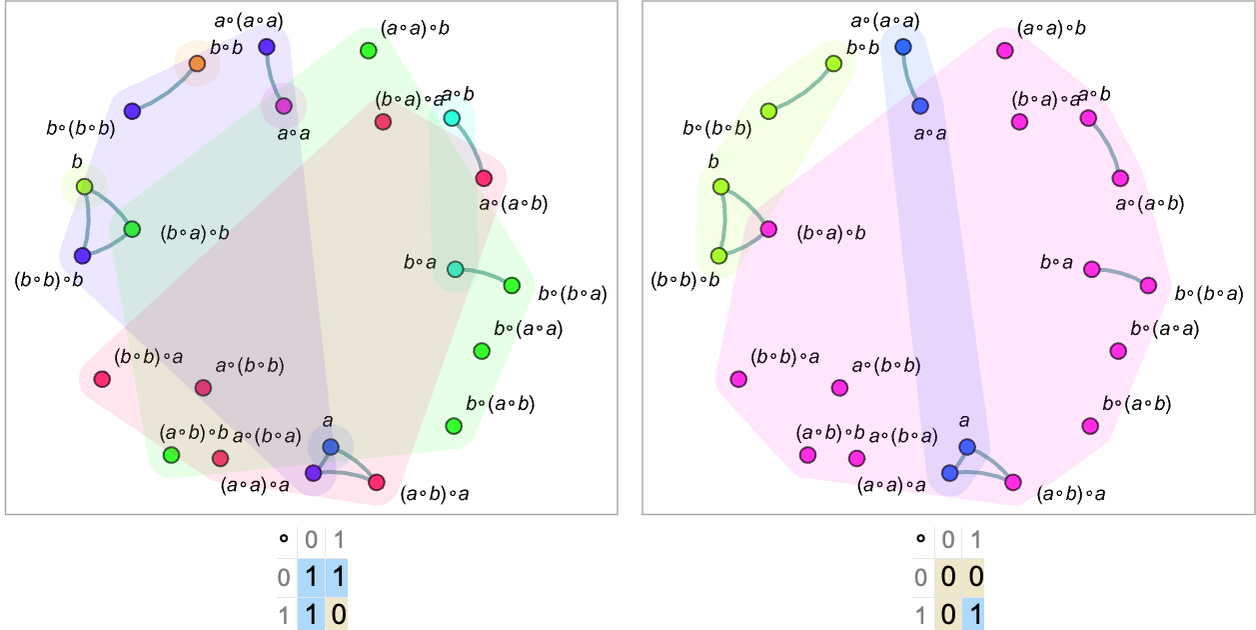
We can think of our graph of equivalences between expressions as corresponding to a slice through an entailment graph—and essentially being “laid out in metamathematical space”, like a branchial graph, or what we’ll later call an “entailment fabric”. And what we see is that when we have a valid model different codes yield different patches that in effect cover metamathematical space in a way that respects the equivalences implied by the underlying axiom system.
But now let’s see what happens if we make an entailment cone, tagging each node with the code corresponding to the expression it represents, first for a valid model, and then for non-valid ones:
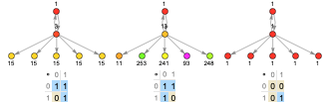
With the valid model, the whole entailment cone is tagged with the same code (and here also same color). But for the non-valid models, different “patches” in the entailment cone are tagged with different codes.
Let’s say we’re trying to see if two expressions are equal according to the underlying axiom system. The definitive way to tell this is to find a “proof path” from one expression to the other. But as an “approximation” we can just “evaluate” these two expressions according to a model, and see if the resulting codes are the same. Even if it’s a valid model, though, this can only definitively tell us that two expressions aren’t equal; it can’t confirm that they are. In principle we can refine things by checking in multiple models—particularly ones with more elements. But without essentially pre-checking all possible equalities we can’t in general be sure that this will give us the complete story.
Of course, generating explicit proofs from the underlying axiom system can also be hard—because in general the proof can be arbitrarily long. And in a sense there is a tradeoff. Given a particular equivalence to check we can either search for a path in the entailment graph, often effectively having to try many possibilities. Or we can “do the work up front” by finding a model or collection of models that we know will correctly tell us whether the equivalence is correct.
Later we’ll see how these choices relate to how mathematical observers can “parse” the structure of metamathematical space. In effect observers can either explicitly try to trace out “proof paths” formed from sequences of abstract symbolic expressions—or they can “globally predetermine” what expressions “mean” by identifying some overall model. In general there may be many possible choices of models—and what we’ll see is that these different choices are essentially analogous to different choices of reference frames in physics.
One feature of our discussion of models so far is that we’ve always been talking about making models for axioms, and then applying these models to expressions. But in the accumulative systems we’ve discussed above (and that seem like closer metamodels of actual mathematics), we’re only ever talking about “statements”—with “axioms” just being statements we happen to start with. So how do models work in such a context?
Here’s the beginning of the token-event graph starting with
produced using one step of entailment by substitution:
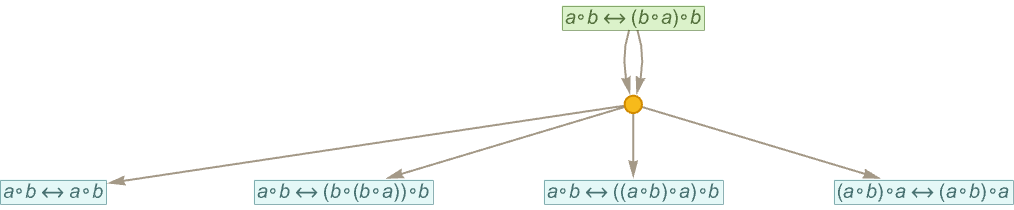
For each of the statements given here, there are certain size-2 models (indicated here by their multiplication tables) that are valid—or in some cases all models are valid:
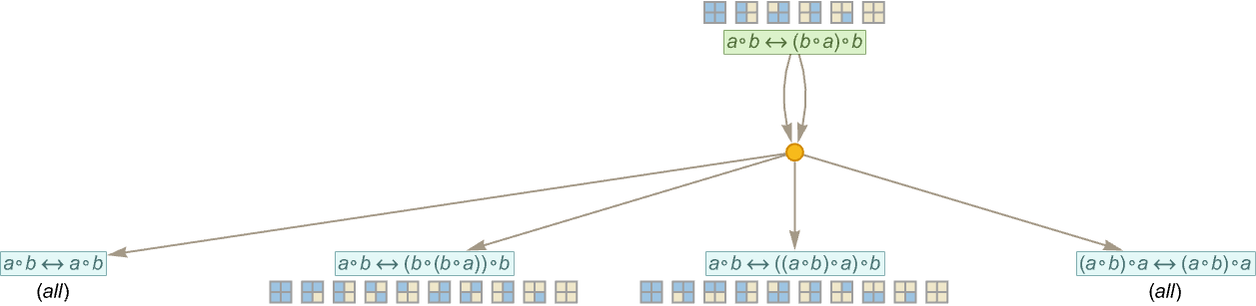
We can summarize this by indicating in a 4×4 grid which of the 16 possible size-2 models are consistent with each statement generated so far in the entailment cone:
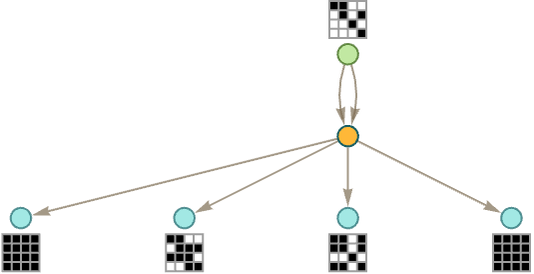
Continuing one more step we get:
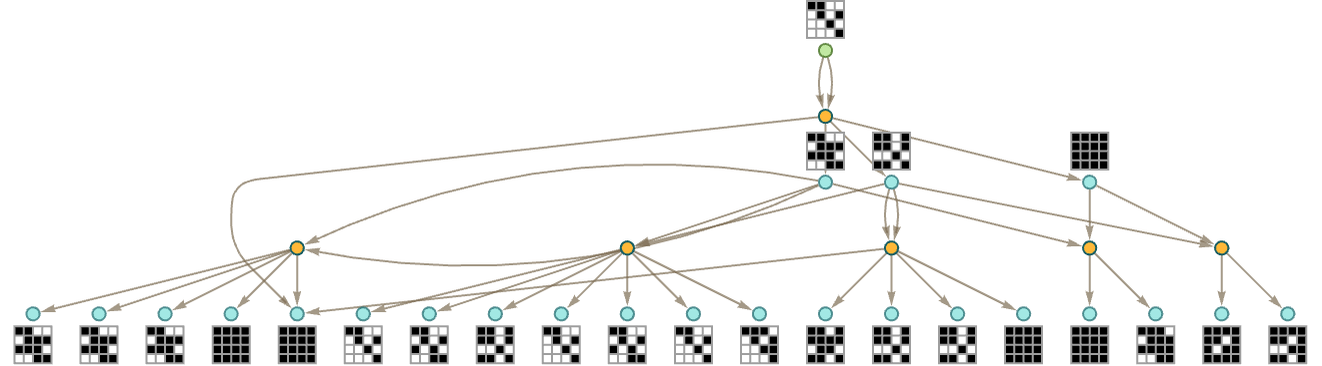
It’s often the case that statements generated on successive steps in the entailment cone in essence just “accumulate more models”. But—as we can see from the right-hand edge of this graph—it’s not always the case—and sometimes a model valid for one statement is no longer valid for a statement it entails. (And the same is true if we use full bisubstitution rather than just substitution.)
Everything we’ve discussed about models so far here has to do with expressions. But there can also be models for other kinds of structures. For strings it’s possible to use something like the same setup, though it doesn’t work quite so well. One can think of transforming the string
into
and then trying to find appropriate “multiplication tables” for ∘, but here operating on the specific elements A and B, not on a collection of elements defined by the model.
Defining models for a hypergraph rewriting system is more challenging, if interesting. One can think of the expressions we’ve used as corresponding to trees—which can be “evaluated” as soon as definite “operators” associated with the model are filled in at each node. If we try to do the same thing with graphs (or hypergraphs) we’ll immediately be thrust into issues of the order in which we scan the graph.
At a more general level, we can think of a “model” as being a way that an observer tries to summarize things. And we can imagine many ways to do this, with differing degrees of fidelity, but always with the feature that if the summaries of two things are different, then those two things can’t be transformed into each other by whatever underlying process is being used.
Put another way, a model defines some kind of invariant for the underlying transformations in a system. The raw material for computing this invariant may be operators at nodes, or may be things like overall graph properties (like cycle counts).